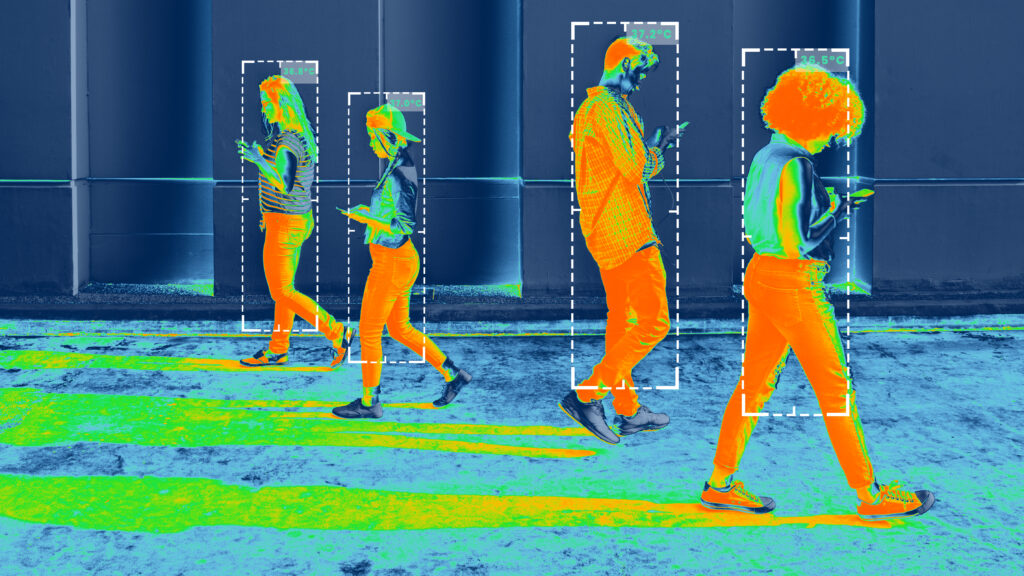
Defined as the process of marking data, data labeling/annotation makes data understandable and interpretable for AI. It is a crucial step in the development of artificial intelligence. Given the volume of data produced, especially with videos, and the subjectivity involved, data labeling/annotation poses a major challenge for companies seeking to leverage data to improve their products and services. The numbers speak for themselves: digital data created worldwide reportedly increased from 2.8 zettabytes in 2012 to 64 zettabytes in 2020 and is projected to reach 2,142 zettabytes in 2035.
This exponential growth of data has led to the emergence of parallel markets such as Data Labeling. A report by NASSCOM, an Indian non-profit organization, suggests that the Data Labeling market could reach up to $4.4 billion by 2023, seven times more than in 2018. This surge is attributed to the fact that AI models need to be constantly trained to autonomously identify objects, audio, visual, and textual content. Thus, annotating and labeling data are indispensable but must not compromise data quality for AI.
Why is data quality important in AI?
Data quality is crucial in AI as it directly affects the accuracy and reliability of results. AI models are trained based on data, and if this data is of poor quality, the model’s results will also be poor.
Data errors can result from various factors, such as data entry errors, missing data, mislabeled data, and measurement errors.
According to an IBM study, data errors can cost businesses up to $3.1 trillion annually. Data errors can also take a long time to correct, delaying AI projects and incurring additional costs.
The data collection, organization, and labeling step should not be overlooked. According to a Cognilytica study, this phase can represent up to 80% of AI projects.
To complement these figures, results from a 2023 Twilio study indicate that 31% of surveyed companies cite poor data quality as a barrier to leveraging AI. Without robust data, AI may fail to deliver experiences up to consumer expectations.
How to improve data quality in AI?
There are several measures that companies can take to improve the quality of their data in AI.
Firstly, it is essential to collect data that represents the problem the model is supposed to solve. The data should also be cleaned to eliminate measurement errors, missing data, and mislabeled data.
It is also important to regularly check the quality of data to ensure they remain representative and reliable. Data can be checked using cross-validation techniques, which involve splitting the data into training and validation sets to assess model performance.
The human dimension is crucial in ensuring data quality for AI. Companies can rely on data labelers, individuals responsible for labeling and cleaning data to ensure they are of quality. Data labelers can identify data errors that may be challenging for AI algorithms to detect. They can also help label data for AI model training, improving prediction quality and reducing bias.
Investing upfront to accelerate Go to Market?
Data quality can significantly accelerate the Go-to-Market of AI. By ensuring that the data used to train models is of quality, companies can reduce the time needed to prepare data and train models. This can enable companies to launch their AI products more quickly, giving them a competitive advantage.
Outsourcing is an option companies can consider to improve the quality of their data for AI. Companies can outsource data collection, labeling, and cleaning to service providers specialized in this field. This option can be particularly useful for companies that lack the resources to perform these tasks internally.
Outsourcing can offer several benefits, including cost reduction and improved data quality. Service providers can use advanced techniques to clean and label data, improving the accuracy and reliability of AI results.
However, outsourcing can also pose risks, such as loss of control over data and data security. Companies must ensure that service providers adhere to data security and privacy standards and have clear data ownership policies.
Implementing quality control measures
It is essential to implement quality control measures to ensure the reliability and accuracy of annotations.
- Development of detailed annotation guidelines: Explain criteria, definitions, and examples for each annotation category or task.
- Quality Control (QC) samples: Regularly provide external annotators with samples of annotations for which correct answers are known, then compare their annotations with reference ones to assess accuracy and consistency.
- Peer reviews: Establish a peer review process, in which annotations by external annotators are reviewed and verified by other qualified annotators or internal project managers.
- Regular communication: Maintain regular communication with external annotators to address their questions, clarify guidelines, and provide feedback on their performance.
- Productivity tracking: Monitor the productivity of external annotators by tracking the number of annotations made per unit of time. This can help identify productivity issues and take corrective actions if necessary.
be ys outsourcing expertise in data processing
With 15 years of expertise, be ys outsourcing services offers efficient Data Annotation services by providing teams of qualified Data Annotators and Labelers to annotate, label, segment, and enrich all types of content in various formats, resulting in functional artificial intelligence solutions.
Would you like to learn more about our Data Annotation offerings?
Visit our website by clicking on the following link: https://www.be-ys-outsourcing-services.com/en/data-annotation-ia/
Or contact us directly at: commercial.outsourcing@be-ys.com
To stay updated with all the latest news from be ys outsourcing services: https://www.linkedin.com/company/be-ys-outsourcingservices/


